ChatGLM-6B 实践分享
最近一直在学习LLM,其中ChatGLM-6B又尤其火爆。所以分享一些相关信息。这次文章比较水,大部分内容都来自官方。
ChatGLM-6B介绍
官网地址:http://chatglm.cn
开发团队:清华&智谱
ChatGLM-6B在2023年3月发布的一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
模型效果
在众多大模型里,ChatGLM-6B效果比较好,还是比较早开源finetune的。属于国内研究LLM比较多的。 * 在5月初的UC伯克利发布的LLM的benchmark排在了第5位,不过目前看已经到了第14位了。
| Rank | Model | Elo Rating | Description |
|---|---|---|---|
| 1 | 🥇 gpt-4 | 1225 | ChatGPT-4 by OpenAI |
| 2 | 🥈 claude-v1 | 1195 | Claude by Anthropic |
| 3 | 🥉 claude-instant-v1 | 1153 | Claude Instant by Anthropic |
| 4 | gpt-3.5-turbo | 1143 | ChatGPT-3.5 by OpenAI |
| 5 | vicuna-13b | 1054 | a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS |
| 6 | palm-2 | 1042 | PaLM 2 for Chat (chat-bison@001) by Google |
| 7 | vicuna-7b | 1007 | a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS |
| 8 | koala-13b | 980 | a dialogue model for academic research by BAIR |
| 9 | mpt-7b-chat | 952 | a chatbot fine-tuned from MPT-7B by MosaicML |
| 10 | fastchat-t5-3b | 941 | a chat assistant fine-tuned from FLAN-T5 by LMSYS |
| 11 | alpaca-13b | 937 | a model fine-tuned from LLaMA on instruction-following demonstrations by Stanford |
| 12 | RWKV-4-Raven-14B | 928 | an RNN with transformer-level LLM performance |
| 13 | oasst-pythia-12b | 921 | an Open Assistant for everyone by LAION |
| 14 | chatglm-6b | 921 | an open bilingual dialogue language model by Tsinghua University |
| 15 | stablelm-tuned-alpha-7b | 882 | Stability AI language models |
| 16 | dolly-v2-12b | 866 | an instruction-tuned open large language model by Databricks |
| 17 | llama-13b | 854 | open and efficient foundation language models by Meta |
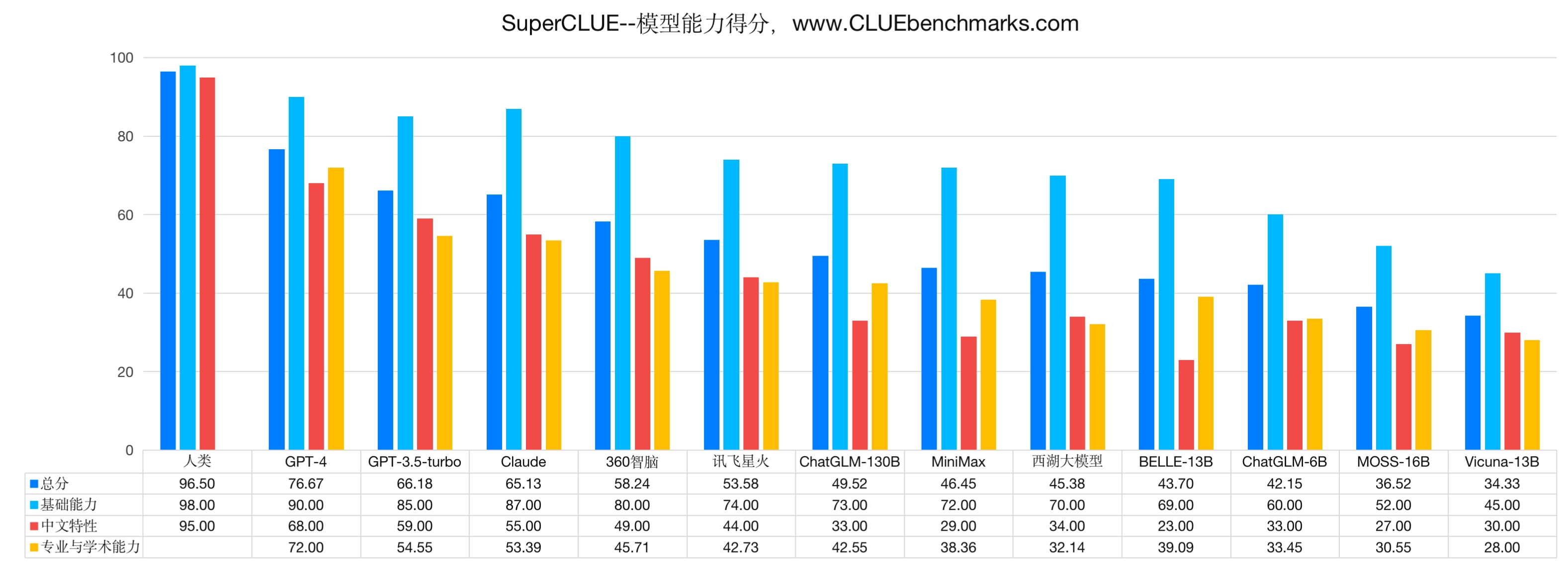
- 在中文的大模型评测SuperCLUE里,目前在第10位(ChatGLM-130B排第6)。
发展历程
1 | flowchart LR |
ChatGLM-6B是基于GLM(General Language Model)模型为基座模型。
- GLM在2022年3月发布于ACL 2022。GLM是一个通用的预训练语言模型。对标于bert和T5。base版本110M。github:https://github.com/thudm/glm
- GLM-130B在2022年10月发布。是基于GLM的双语双向稠密模型。参数量130B。对标于GPT3和ERNIE TITAN。github: https://github.com/THUDM/GLM-130B
- ChatGLM-6B在2023年3月开源,5月发布了v1.1版本。模型提供finetune。github: https://github.com/THUDM/ChatGLM-6B
- ChatGLM-130B目前正在内测。属于智谱的商业化版本。内测地址:https://chatglm.cn/
- VisualGLM-6B在2023年5月发布的支持图像理解的多模态对话语言模型。github: https://github.com/THUDM/VisualGLM-6B
GLM模型简介
GLM为了同时解决NLU、无条件生成和条件生成3个任务而提出的基于自回归文本填空的预训练语言模型。
解决问题:
- NLU(自然语言理解)
- Unconditional generation(无条件文本生成)
- Conditional generation(条件文本生成)
核心方案:Autoregressive Blank Infilling(自回归文本填空)
1. 训练目标:自回归文本填空
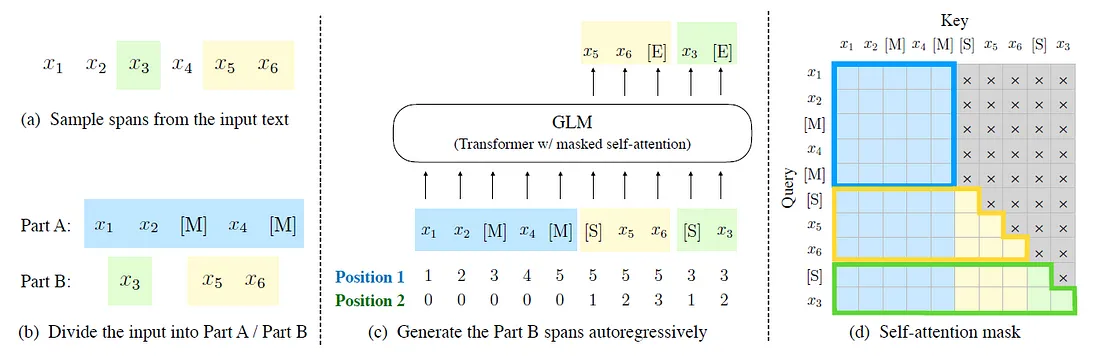 1.
原始文本为[x1,x2,x3,x4,x5,x6]。从中采样两个片段[x3]和[x5,x6]。 2.
在A部分将采样出来的片段替换为[M],并在B部分打乱这些片段。 3. GLM
自回归生成B部分。每个片段作为输入时都要在前面添加[S],在后面添加[E]。2D
位置编码表示跨度之间和跨度内部的位置。 4.
自注意力掩码。灰色区域被隐藏。A部分的token可以关注自己(蓝色框架),但不能关注B部分。B部分的令牌可以关注A部分和它们在B部分中的前身(黄色和绿色框架对应于两个跨度)。
[M]:= [MASK],[S]:= [START],[E]:= [END]。
1.
原始文本为[x1,x2,x3,x4,x5,x6]。从中采样两个片段[x3]和[x5,x6]。 2.
在A部分将采样出来的片段替换为[M],并在B部分打乱这些片段。 3. GLM
自回归生成B部分。每个片段作为输入时都要在前面添加[S],在后面添加[E]。2D
位置编码表示跨度之间和跨度内部的位置。 4.
自注意力掩码。灰色区域被隐藏。A部分的token可以关注自己(蓝色框架),但不能关注B部分。B部分的令牌可以关注A部分和它们在B部分中的前身(黄色和绿色框架对应于两个跨度)。
[M]:= [MASK],[S]:= [START],[E]:= [END]。
2. 多任务预训练
GLM是如何兼顾NLU和NLG?
多目标设置:目标1:文本填空。目标2:生成更长的文本。
如何做的?
在GLM-130B的实现中,有两种不同的MASK标识符,表示两个不同的目的:
[MASK]根据泊松分布 (\(\lambda=3\))对输入中标识符进行短跨度的采样:限制masked span必须是完整的句子。多个span(句子)被采样,以覆盖15%的原始标记。这个目标是针对seq2seq任务。起预冲汪汪是完整的句子或者段落。
[gMASK]掩盖一个长的跨度,从其位置到整个文本的结束。span长度从原始长度的50%-100%抽取。目标旨在生成长文本。
[sop]标识符表示一个片断的开始,[eop]表示一个片断的结束。这两个目标在GLM-130B的预训练中是混合的,分别占预训练标记的30%和70%。
GLM利用自回归文本填空作为其主要的预训练目标。它掩盖了随机的连续跨度(例如,下面的例子中的 "complete unknown"),并对其进行自回归预测。上下文之间的注意力(例如,"like a [MASK], like a rolling stone")是双向的。相反,被掩盖的标记之间的注意力,和从上下文到被掩盖的标识符的注意力是自回归掩码的。

3. 模型架构调整
GLM还是采用的transformer基础架构。在此基础上做了一些调整。
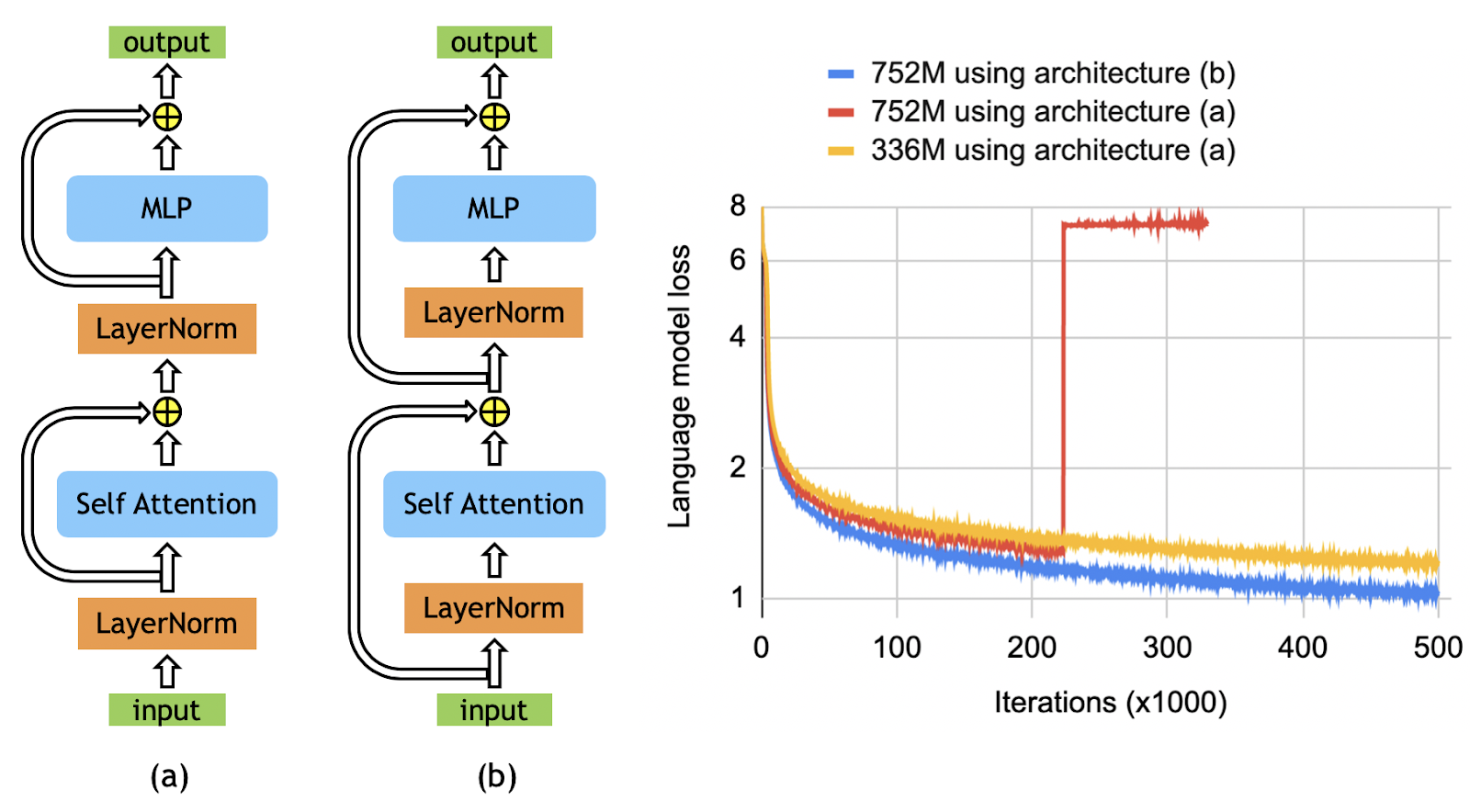 (
(GLM-130B在此基础上进一步做了一些调整:
- 采用旋转位置编码(RoPE)
- 归一化:使用DeepNet的Post-LN
- 前馈网络:Gated Linear Unit(GLU) + GeLU作为激活函数
4. GLM模型与参数
具体模型和参数列表:
| Name | Params | Language | Corpus | Objective | File | Config |
|---|---|---|---|---|---|---|
| GLM-Base | 110M | English | Wiki+Book | Token | glm-base-blank.tar.bz2 | model_blocklm_base.sh |
| GLM-Large | 335M | English | Wiki+Book | Token | glm-large-blank.tar.bz2 | model_blocklm_large.sh |
| GLM-Large-Chinese | 335M | Chinese | WuDaoCorpora | Token+Sent+Doc | glm-large-chinese.tar.bz2 | model_blocklm_large_chinese.sh |
| GLM-Doc | 335M | English | Wiki+Book | Token+Doc | glm-large-generation.tar.bz2 | model_blocklm_large_generation.sh |
| GLM-410M | 410M | English | Wiki+Book | Token+Doc | glm-1.25-generation.tar.bz2 | model_blocklm_1.25_generation.sh |
| GLM-515M | 515M | English | Wiki+Book | Token+Doc | glm-1.5-generation.tar.bz2 | model_blocklm_1.5_generation.sh |
| GLM-RoBERTa | 335M | English | RoBERTa | Token | glm-roberta-large-blank.tar.bz2 | model_blocklm_roberta_large.sh |
| GLM-2B | 2B | English | Pile | Token+Sent+Doc | glm-2b.tar.bz2 | model_blocklm_2B.sh |
| GLM-10B | 10B | English | Pile | Token+Sent+Doc | Download | model_blocklm_10B.sh |
| GLM-10B-Chinese | 10B | Chinese | WuDaoCorpora | Token+Sent+Doc | Download | model_blocklm_10B_chinese.sh |
5. 值得一提
GLM使用的词表和分词器是基于icetk实现的。icetk是一个统一的图像、中文和英文的多模态标记器。
这个使得后面的多模态模型可以在统一的GLM下实现。
不过也导致了ChatGLM-6B在加载时tokenizer的速度较慢。
对于ChatGLM的预训练方式,官网上只是简单说明类似于ChatGPT的训练方式。并没有提供预训练数据和代码。
ChatGLM-6B的Licence是非商业的。不可用于商业用途。
GLM-130B预训练
GLM-130B的官网上对GLM-130B的预训练介绍算是比较详细的了。这里也简单介绍一下。
 (截至2022年7月31日,训练GLM-130B遇到和解决的主要问题的时间轴)
(截至2022年7月31日,训练GLM-130B遇到和解决的主要问题的时间轴)
GLM-130B的预训练使用了超过4000亿个文本标记。包含自监督预训练语料(95%)和多任务指令预训练(5%)
自监督预训练语料使用了1.2T的英文Pile的语料和1.3T中文语料。多任务指令预训练(MIP)使用TO(包含T0++)和DeepStruct的数据。
预训练持续了60天,使用了96个DGX-A100(40G)节点, 等价于490万美元的云服务费用(由智谱赞助)。
最关键的挑战:训练稳定性
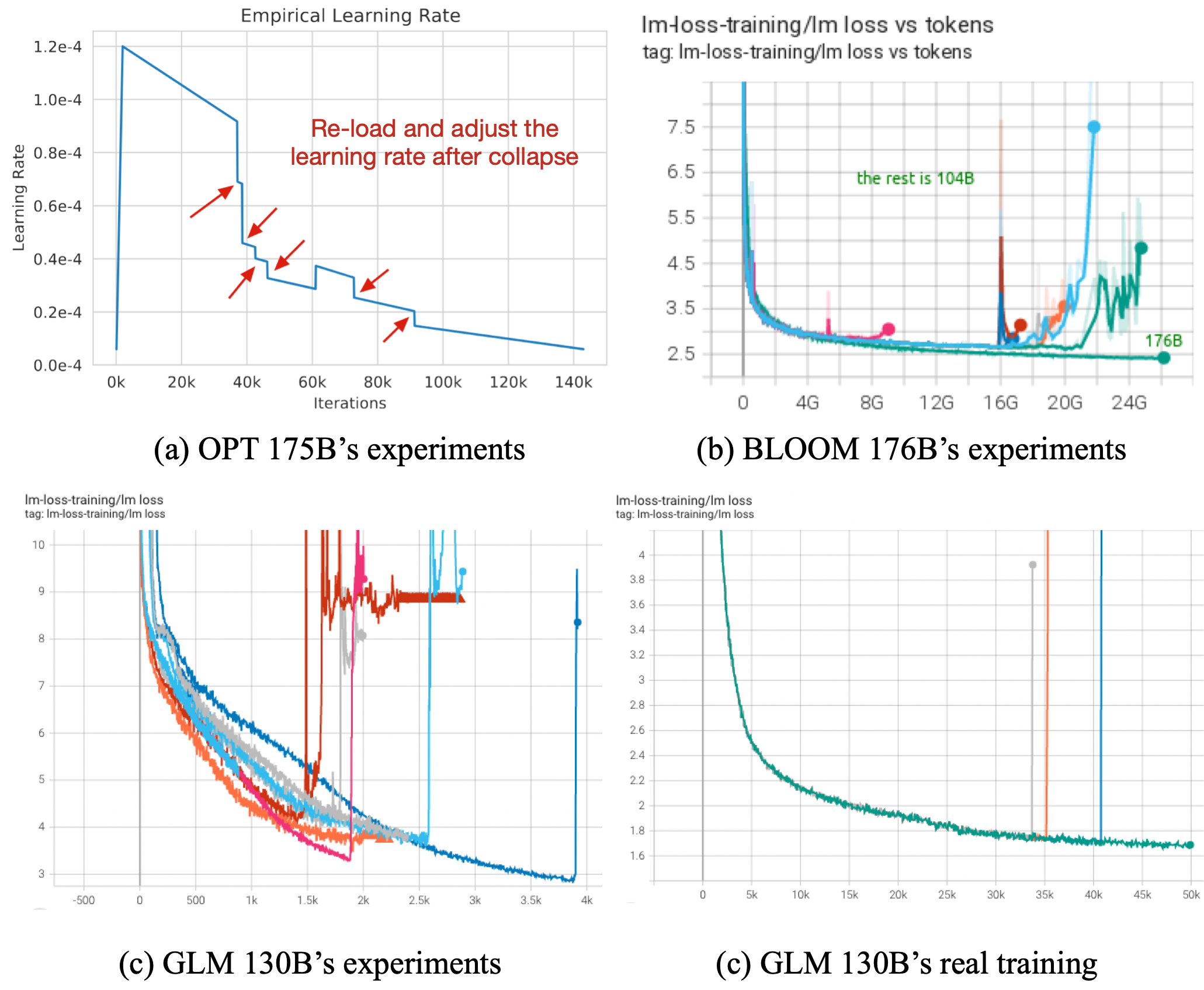 (所有模型都面临训练不稳定,它可能发生在预训练的开始、中间或结束阶段(图(a)和(b)分别取自OPT和BLOOM))
(所有模型都面临训练不稳定,它可能发生在预训练的开始、中间或结束阶段(图(a)和(b)分别取自OPT和BLOOM))
GLM-130B的方案: 1. 浮点数格式:FP16混合精度 为了平衡效率和稳定性。采用FP16是为了在多平台下都可支持。因此NV提供的BF16没有被采用。 2. 嵌入层:梯度缩减 缩小嵌入层\(\alpha = 0.1\)。避免训练过程中,嵌入层梯度范数激增导致训练崩溃。 3. 注意力计算:FP32 softmax 从本质上讲,崩溃是由异常的损失 "梯度"形成的,要么是由于噪声数据,要么是正向计算中的精度上溢或者下溢。 在LLM中,注意力计算操作最容易上溢或下溢。这里没有采用CogView中提出的PB-Relax(因为PB-Relax在GLM-130B训练很慢),而是直接在计算softmax中使用FP32来扩展精度。
GLM-130B的参数配置为:
| 层数 | 隐层维度 | GeGLU 隐层维度 | 注意力头数量 | 最大序列长度 | 词表大小 |
|---|---|---|---|---|---|
| 70 | 12,288 | 32,768 | 96 | 2,048 | 150,000 |
ChatGLM-6B部署
硬件需求
官网的硬件要求,相对于其他LLM,属于门槛比较低的。在量化情况下,甚至可以使用CPU进行推理。
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
镜像选择
cuda11.3-cudnn8-devel-ubuntu18.04-pt1.10.2:v2
os版本上需要选择18.04以上,才能支持transformers对应的C++ lib。
GPU: V100 32G
下载安装
1 | pip install -r requirements.txt |
可以直接调用提供的终端client: 1
python cli_demo.py
PS:最近huggingface不太稳定,如果下载断了,可以多尝试几次。或通过手动下载:https://huggingface.co/THUDM/chatglm-6b/tree/main
下载后的文件列表: 1
2
3
4config.json modeling_chatglm.py pytorch_model-00004-of-00008.bin pytorch_model-00008-of-00008.bin tokenizer_config.json
config.json.bak pytorch_model-00001-of-00008.bin pytorch_model-00005-of-00008.bin pytorch_model.bin.index.json
configuration_chatglm.py pytorch_model-00002-of-00008.bin pytorch_model-00006-of-00008.bin quantization.py
ice_text.model pytorch_model-00003-of-00008.bin pytorch_model-00007-of-00008.bin tokenization_chatglm.py1
Loading checkpoint shards: 62%|████████████████████████████████████████████████████████▎ | 5/8 [00:44<00:27, 9.06s/it]
1 |
|
ChatGLM-6B Finetune
ChatGLM支持多种预训练方式,如:ptuning v2(官方),lora 等。下面说一下官方的Finetune方式。
根据ChatGLM-6B官方的微调教程进行实战。官方文档:https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
对于ChatGLM-6B模型基于P-Tuning v2的微调。P-Tuning v2 将需要微调的参数量减少到原理的0.1%,再通过模型量化、Gradient Checkpoint等方法,最低只需要7GB显存即可运行。
环境搭建
继续使用之前搭建的chatglm-6B的环境。主要依赖有torch 1.12, transformers 4.27.1以上。
新增的依赖有: rouge_chinese, nltk, jieba, datasets
训练数据
官网提供的例子需要单独下载数据集:AdvertiseGen。
地址:https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
任务描述:根据商品内容的tag生成一段广告词。
数据为json格式,content是产品标签。summary为label。
举个例子: 1
2
3{"content": "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞", "summary": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。"}
{"content": "类型#裙*材质#针织*颜色#纯色*风格#复古*风格#文艺*风格#简约*图案#格子*图案#纯色*图案#复古*裙型#背带裙*裙长#连衣裙*裙领型#半高领", "summary": "这款BRAND针织两件套连衣裙,简约的纯色半高领针织上衣,修饰着颈部线,尽显优雅气质。同时搭配叠穿起一条背带式的复古格纹裙,整体散发着一股怀旧的时髦魅力,很是文艺范。"}
{"content": "类型#上衣*风格#嘻哈*图案#卡通*图案#印花*图案#撞色*衣样式#卫衣*衣款式#连帽", "summary": "嘻哈玩转童年,随时<UNK>,没错,出街还是要靠卫衣来装酷哦!时尚个性的连帽设计,率性有范还防风保暖。还有胸前撞色的卡通印花设计,靓丽抢眼更富有趣味性,加上前幅大容量又时尚美观的袋鼠兜,简直就是孩子耍帅装酷必备的利器。"}1
sh -x train.sh
模型推理
执行脚本evaluate.sh 1
sh -x evaluate.sh
| prompt | before finetune | after finetune |
|---|---|---|
| 类型#上衣风格#嘻哈图案#卡通图案#印花图案#撞色衣样式#卫衣衣款式#连帽 | 嘻哈风格的图案设计,卡通和印花元素的融合,以及撞色的搭配,选择卫衣搭配牛仔裤或运动鞋,在街头巷尾展现个性时尚。 | 卫衣是春天必不可少的时尚单品,这款卫衣采用撞色设计,时尚减龄,彰显年轻活力,彰显个性,充满了减龄的嘻哈范儿,让穿着者瞬间变得年轻时尚,充满了活力,展现时尚范儿,时尚元素和个性元素共同结合,充满了个性,同时,连帽卫衣 |
其他:VisualGLM
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisualGLM-6B 依靠来自于 CogView 数据集的30M高质量中文图文对,与300M经过筛选的英文图文对进行预训练,中英文权重相同。该训练方式较好地将视觉信息对齐到ChatGLM的语义空间;之后的微调阶段,模型在长视觉问答数据上训练,以生成符合人类偏好的答案。
VisualGLM-6B 由 SwissArmyTransformer(简称sat) 库训练,这是一个支持Transformer灵活修改、训练的工具库,支持Lora、P-tuning等参数高效微调方法。本项目提供了符合用户习惯的huggingface接口,也提供了基于sat的接口。
结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需8.7G显存)。
demo演示
这张图是我们CV模型没有打上"猫"这个tag的一张图片case。

看下使用VisualGLM-6B的效果:
1 | 欢迎使用 VisualGLM-6B 模型,输入图片路径和内容即可进行对话,clear 清空对话历史,stop 终止程序 |
LLM的另外一种打开方式
目前主流的本地化方式除了finetune LLM外,还有一种就是使用langchain的方式。langchain同时也支持在线LLM api的调用。
langchain实现原理如下图所示,过程包括加载文件 -> 读取文本 ->
文本分割 -> 文本向量化 -> 问句向量化 ->
在文本向量中匹配出与问句向量最相似的top k个 ->
匹配出的文本作为上下文和问题一起添加到prompt中 ->
提交给LLM生成回答。

finetune与langchain的对比
| 对比 | finetune | langchain |
| 原理 | 在基础大模型上,基于领域数据微调训练一个私有化部署的、数据安全的领域模型 | 利用输入的问题,依靠表征寻找到相似的知识段落文本。将相似知识段落文本拼接上问题输入对话式语言模型,获取当前问题的文档问答结果。 |
| 优点 | 私有化部署 | 私有化部署 |
| 数据安全 | 灵活易扩展 | |
| 更擅长特定行业 | 数据安全 | |
| 缺点 | 模型微调成本较高 | 依赖知识库建设 |
| 数据更新的实时性较差 | 依赖LLM的基础能力 | |
| 经验主义 | 依赖表征模型的能力 | |
| 总结 | 专业化 | 平民化 |
langchain-ChatGLM 本地知识库
一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
从文档处理角度来看,实现流程如下:

下面是langchain-ChatGLM的prompt template 1
2
3
4
5# 基于上下文的prompt模版,请务必保留"{question}"和"{context}"
PROMPT_TEMPLATE = """已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""
question: 是用户的原始问题。
总结
- ChatGLM-6B是一个优秀的支持中文大模型。效果好,不吃配置, 部署简单。
- ChatGLM-6B是基于GLM和GLM-130B而来。GLM是一个双向稠密模型。核心采用了自回归文本填空的训练方式。LLM的预训练很贵。
- ChatGLM-6B可以采用ptuning,lora等多种finetune方式。
- ChatGLM-6B不可商用。不过私有化部署好像可以申请licence。已经有很多公司基于ChatGLM-130B发布了自己的LLM。
参考
- ChatGLM官网:https://chatglm.cn/
- ChatGLM-6B github: https://github.com/THUDM/ChatGLM-6B
- GLM github: https://github.com/THUDM/GLM
- GLM-130B github: https://github.com/THUDM/GLM-130B
- UC伯克利 LLM benchmark: https://chat.lmsys.org/?leaderboard
- GLM论文解读: https://sh-tsang.medium.com/review-glm-general-language-model-pretraining-with-autoregressive-blank-infilling-c217bc91b7d5
- VisualGLM-6B github: https://github.com/THUDM/VisualGLM-6B
- langchain-ChatGLM github: https://github.com/imClumsyPanda/langchain-ChatGLM