Transformer原理——Open AI 和 DeepMind使用的神经网络
本文翻译自:How Transformers Work - The Neural Network used by Open AI and DeepMind
作者:Giuliano Giacaglia,本文主要介绍了Transformer的原理和设计过程。
本文的精华在于阐述了Transformer为什么这样设计,通过RNN,attention,CNN一步一步推出了Transformer的设计原理。使得我们对Transformer的架构有了更深入的认识。
这也是我翻译的第一篇外文,有不妥的地方还望指正。量子位也翻译过这篇文章,可以参考:https://zhuanlan.zhihu.com/p/59422975
[toc]
如果你喜欢这篇文章已经而且想学习机器学习算法的原理,提升方法,应用范围,我建议follow:
Making Things Think:How AI and Deep Learning Power the Products We Use
Transformer是当下非常流行的神经网络架构。Transformer最近被OpenAI用于他们的语言模型,以及被DeepMind用于AlphaStar(可以打败顶级选手的星际争霸AI)上。
Transformer被开发出来解决序列转换和机器翻译问题。这种任务就是任意一个输入序列经过转换变成一个输出序列。任务包括了语音识别,文本语音转换,等等……

对于序列转换模型,必须要有些记忆力机制。例如,我们将下面的句子翻译成另外的语言(法语):
"The Transformers" are a Japanese[[hardcore punk]] band. The band was formed in 1968, during the height of Japanese music history"
"The Transformers"是一个日本乐队(硬核朋克)。这支乐队成立于1968年,正值日本音乐史的鼎盛时期。
在这个例子中,第二句中的"the band"指的是第一句中的"The Transformers"。当你读到第二句时,你知道它的指代。这在翻译中非常重要。在句子中的指代前面的词这样的句子有很多。
为了翻译好这样的句子,模型需要找出这些依赖合联系。循环神经网络(RNN)和卷积神经网络(CNN)正由于它们的特性来用以解决这个问题。我们来回顾一下这两个网络架构和他们的劣势。
循环神经网络(RNN)
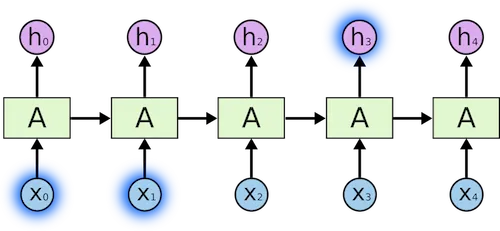
RNN是有循环结构,可以使信息持久。

上图中,我们看到部分神经网络,A,处理输入\(x_t\)和输出\(h_t\)。循环结构可以使信息一步一步传递。
从另外的角度看循环。一个RNN可以认为是相同网络A的多个拷贝,每个网络传递消息到下一个网络。想象一下如果我们把循环展开:
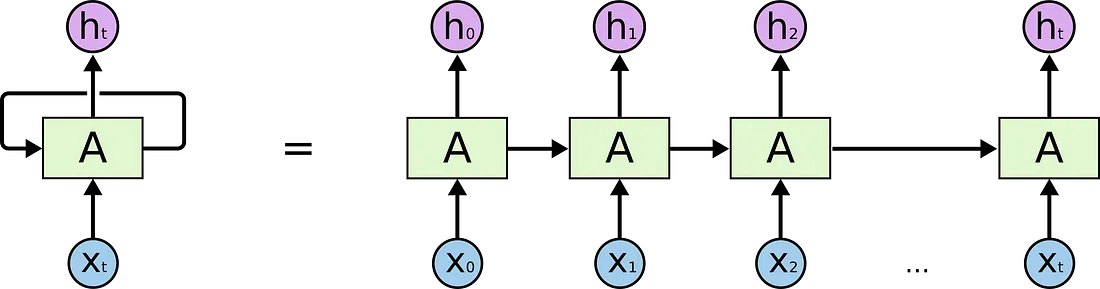
这种链式结构,天然使得RNN与序列和列表显著相关。这种情况下,如果我们想翻译文本,我们可以将文档的单次作为每次的输入。RNN会把上一个单词的信息传递给下一个单词并利用。
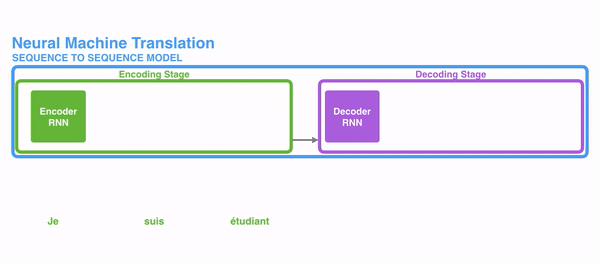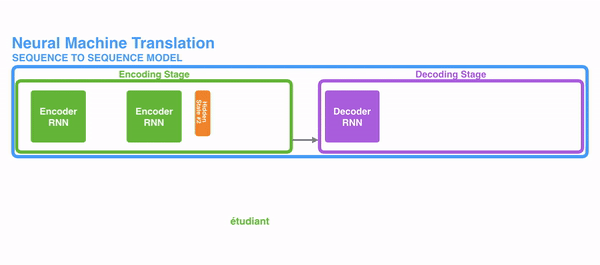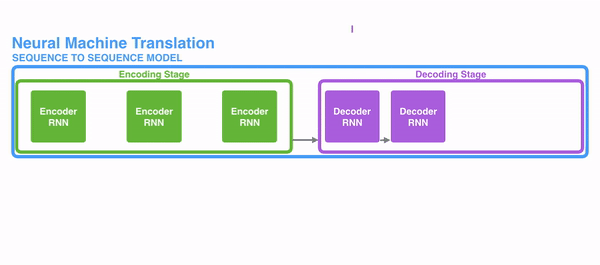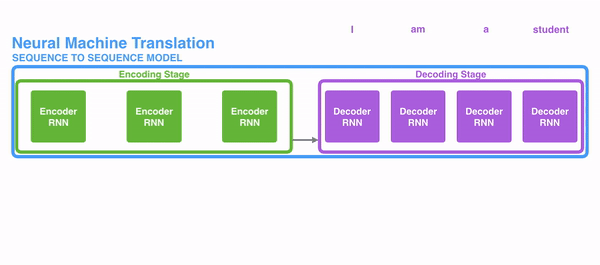
下图表示了seq2seq模型使用RNN是怎么工作的。每个词都单独处理,然后通过隐状态传递给decoding阶段来生成结果句子,并输出。
长时依赖问题
假设语言模型正在根据前一个词预测下一个词。如果我们在预测句子"the clouds in the sky"(天空中的云彩),我们不需要更多上下文。很明显下一个词就是sky。
在这个例子中,相关信息和位置直接的不同差距就很小,RNN可以使用前面的信息找到句子中的下一个词。
但有些情况下,我们需要更多的上下文。例如:当你想要预测下面文本最好的词时:"I grew up in France... I speak fluent ..."。最近的信息表明下一个词可能是一门语言,但如果我们想确定是什么语言,我们需要从上面的文本中找到"France"这个上下文。
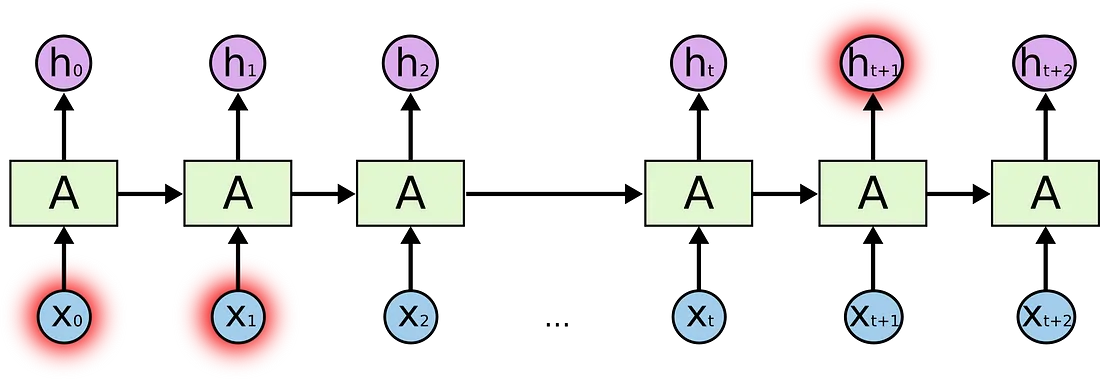
当相关信息和我们需要的位置间距非常大时,RNN就不是非常有效了。这是因为信息是逐层传递的,链条越长,信息在链条上越有可能丢失。
长短时记忆(LSTM)
当安排一天的日程是,我们优先安排我们的约会。如果有更重要的事情,我们会取消一些约会来应对更重要的事情。
RNN不是这样。当它加入新的信息,它都会通过一个方法完全转化已有信息。这个信息会被修改,而没有考虑哪些信息重要,哪些不重要。
LSTM通过加法和乘法对信息进行了小修改。在LSTM中,信息通过一种被称为单元状态的机制传递。在这个机制下,LSTM可以选择记住或遗忘重要的或不重要的信息。
在内部,LSTM构造如下:
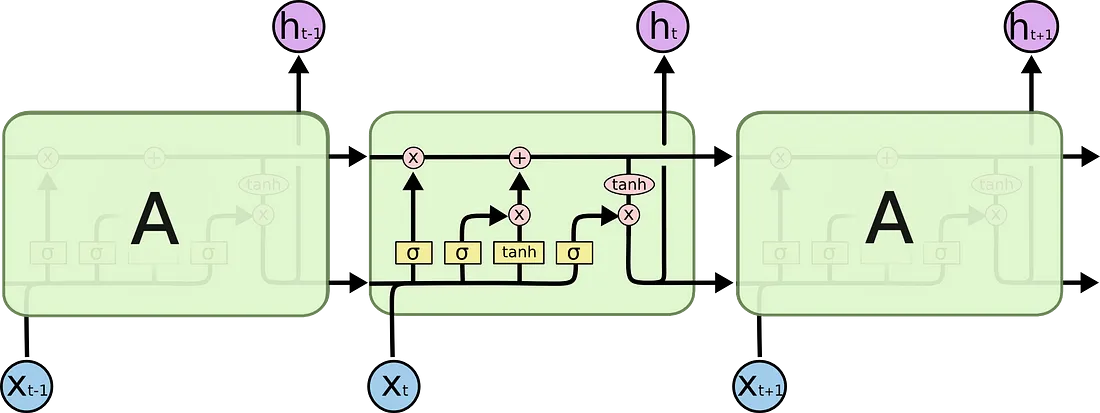
每一个单元将\(x_t\)(句子到句子翻译中的一个词)、前面单元的状态和前面单元的输出共同作为本单元的输入。它操控这些输入,基于这些输入产生新的单元状态和输出。这里不深入讨论每个单元的内部机制细节。如果你想了解单元的原理,我推荐Christopher's 的博客文章:
Understanding LSTM Networks -- colah's blog
在单元状态下,句子中对于翻译一个词的重要信息可以从一个单词到另一个单词这样传递下来。
LSTM的问题
通常RNN遇到的问题LSTM也同样会发生,当句子太长时,LSTM同样处理不好。原因是由于保留对于当前词很远的一个词上下文的概率与它的距离程指数级递减。
这意味着如果句子很长,模型经常会遗忘序列中较远位置的信息。另外一个与RNN相同的问题,LSTM很难并行处理句子,因为它必须逐个词来进行处理。不仅如此,还没有长短期依赖的模型。总结起来有3个问题:
- 顺序计算阻碍并行化
- 没有对长短距离依赖关系进行明确的建模
- “距离”在位置之间是线性的
attention 注意力
为了解决这些问题,研究人员建立了一项技术:对于特别的词给予注意力。
当翻译一句话时,对于我正在翻译的词给予特别的注意力。当我听写一段音频记录时,对于我正在写下的段落听得特别认真。还有当你让我描述我所在的房间时,我会浏览周围的事物并描述。
神经网络利用注意力机制(attention)来实现相同的行为,重点关注所给信息的部分内容。举例来说,一个RNN可以关注另一个RNN的输出。在每个时间步时,它关注于其他RNN的不同位置。
为了解决这些问题,神经网络里使用注意力机制。对于RNN来说,替代原来的整个句子作为一个隐状态,现在每个词都有一个相关的隐状态会输出到decoding阶段。然后这些隐状态会用在RNN decode的每一步。下面的gif表现了这个机制。
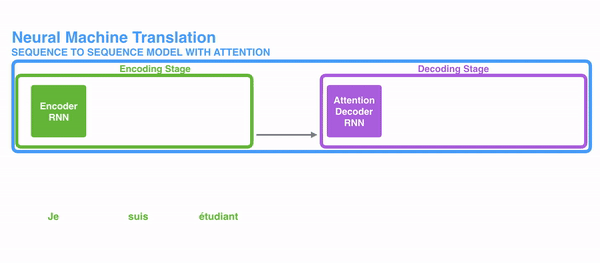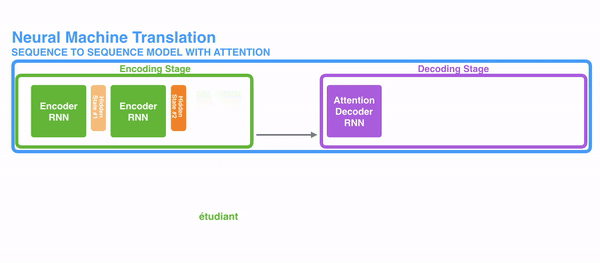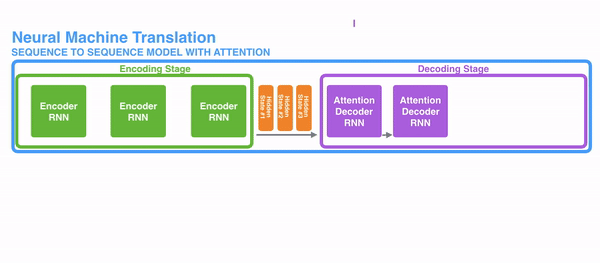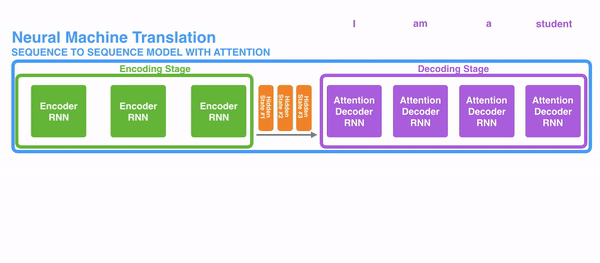
这个机制背后的逻辑是在一个句子中每一个词都有可能包含相关信息。所以为了使decoding更精确,需要利用注意力机制把输入的所有词都考虑进去。
对于把注意力机制引入RNN的序列转导(seq2seq)任务时,我们把任务分为encoding和decoding两个主要步骤。如图中一个用绿色表示,一个用紫色表示。绿色步骤被称为encoding阶段(编码阶段),紫色步骤被称为decoding阶段(解码阶段)。

绿色步骤主要负责建立输入的隐状态。不同于之前只把一个隐藏层输入给decoders,利用注意力机制,我们把句子中每一个词产生的隐藏层都输出给decoding阶段。通过把每一个状态都用于decoding阶段,来计算出网络中哪些部分是需要重点关注的。
举例来说,当翻译法语句子”“Je suis étudiant”到英语时,翻译不同的词时,decoding截断需要关注这些词。
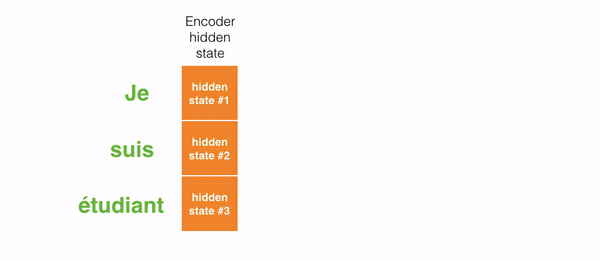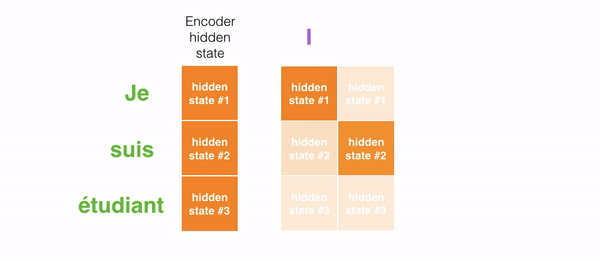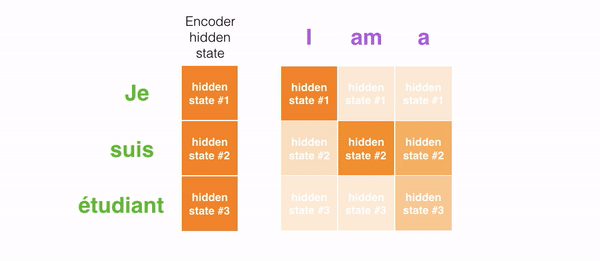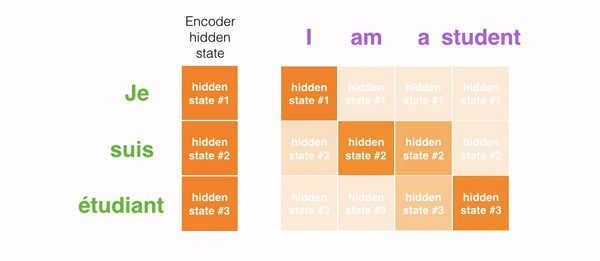
再比如下面这张图,当你把法语 “L’accord sur la zone économique européenne a été signé en août 1992.” 翻译成英语时,对于每个输入需要多少注意力。

虽然引入了注意力机制,但我们前面讨论的问题仍然无法用RNN来解决。比如:不能并行处理输入内容(输入的词汇)。对于比较大的文本语料,这将增加文本的翻译时间。
卷积神经网络(CNN)
卷积神经网络可以帮助解决下列问题: * 轻而易举地并行化(对于每层来说) * 利用局部依赖 * 位置距离是对数的(输出和输入的CNN计算复杂度\(O(N)=log(N)\))
对于序列转导最流行的一下网络结构,比如Wavenet和Bytenet,就是CNN的。

CNN可以并行处理的原因是输入的每一个词都可以同时被处理翻译,不需要依赖前面的词。不止如此,输出和输出的“距离”是时间复杂度\(O(log(N))\)——从输出到输入生成树的高度(从上面的GIF可以看出,对于RNN的计算复杂度\(O(N)\)要好很多。)
Transformers
为了解决并行化的问题,Transformers试图使用带有注意力机制的encoder和decoder来解决。注意力机制提升模型序列翻译的速度。
让我们来看一下Transformers是如何工作的。Transformers是使用注意力机制提速的一种模型。更确切的说,它使用自注意力机制。

在内部,Transformer有着一个与之前模型相似的架构。但Transformer有6个encoder和6个decoder组成。
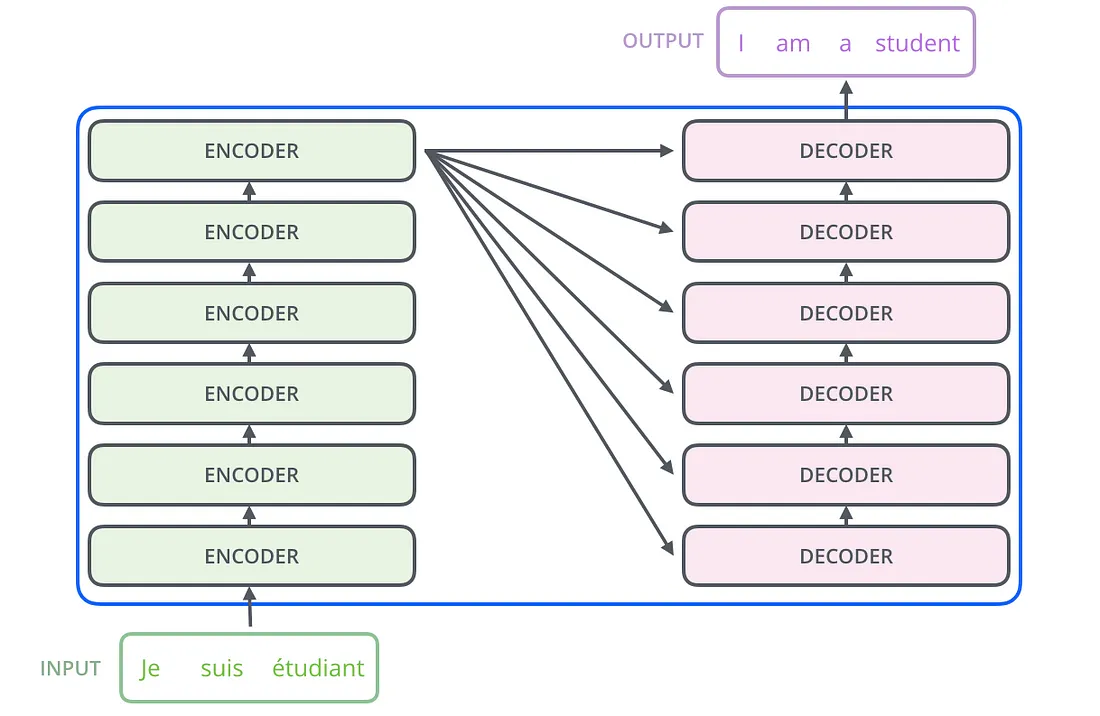
每一个encoder都是非常相似的。所有的encoder都有相同的架构。所有decoder则分享相同的特性,比如他们也都是非常相似的。每个encoder有2层组成:自注意力机制层和全连接层。
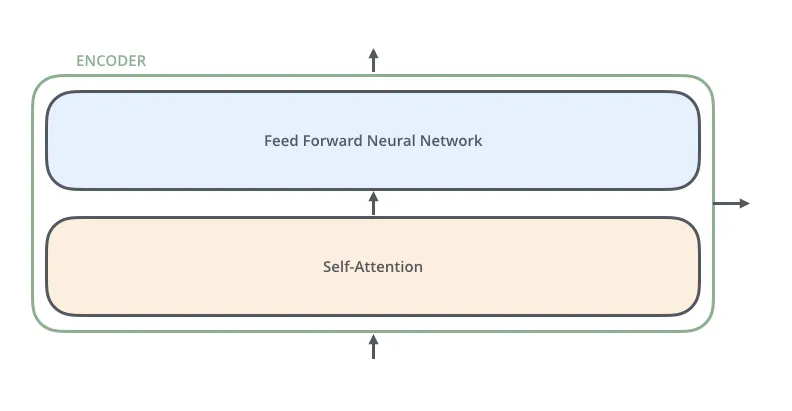
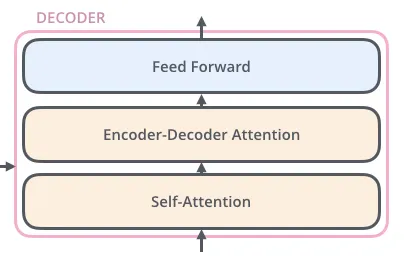
encoder的输入首先通过自注意力层。它帮助encoder对某个词根据句子中的其他词进行编码。decoder也有这些层,但在他们之间,有一个注意力层来帮助decoder关注输入句子中的相关部分。
自注意力机制
Note:这部分来自Jay ALLamar 的博客文章
我们开始来看看各种向量/张量以及它们如何在这些组件之间从一个训练模型的输入变成输出的。通常在NLP应用的情况是,我们把输入词通过词嵌入算法(embedding algorithm)变成一个向量。

每一个词把词嵌入成一个长度为512的向量。我们将通过这些单块表示那些向量。
词嵌入一般只在encoder的最底部发生。这个抽象对于所有encoder都是普遍的。他们都会收到一个向量列表,其中每个向量的长度都是512.
对于底部的encoder会进行词嵌入,但对于其他encoder,输入会是底部encoder的直接输出。在我们输入序列词嵌入之后,它们都会通过每个encoder的两层。
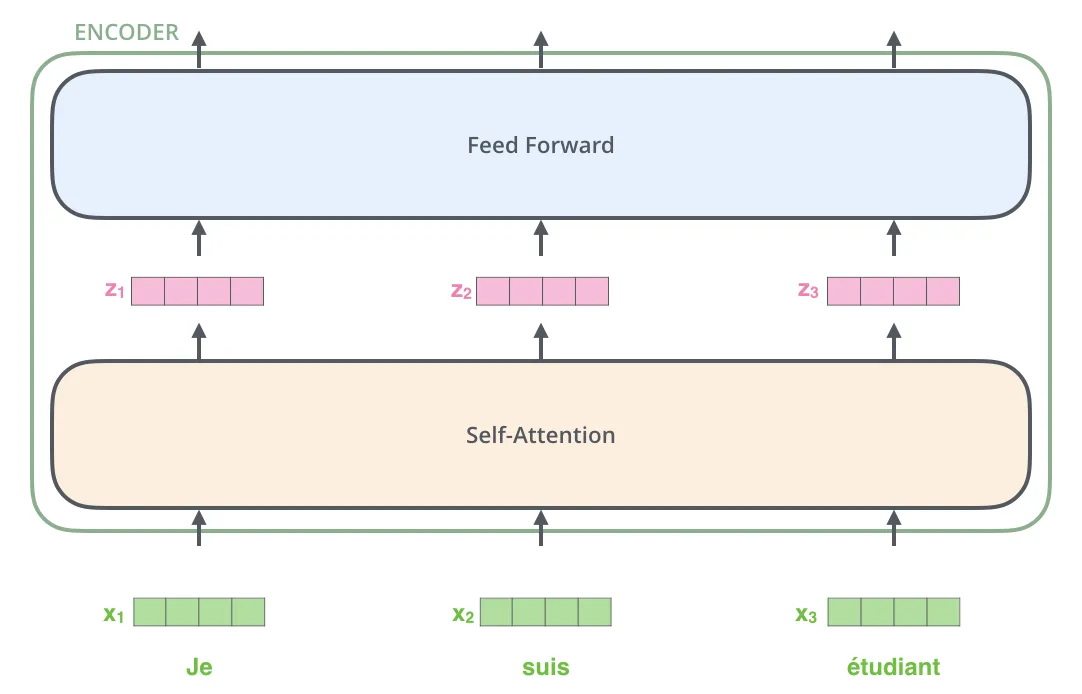
这里我们开始看到Transformer的一个关键特性:每一个位置上的词都通过它自己路径上的encoder。在自注意力层这些路径有互相依赖。但在全连接层没有那些依赖,因此这些路径可以在通过全连接层时并行的执行。
接下来,我们将通过一个更短的句子作为例子,来看看在每一个encoder的子层中发生了什么。
自注意力
我们首先来看看如果使用向量来计算自注意力,然后来看看它具体是如何实现的——通过矩阵运算。
计算自注意力的第一步就是从encoder的输入向量(例子中,每个词的词嵌入向量)中建立3个新向量。所以对于每个词,我们建立一个Query向量,一个Key向量,和一个Value向量。这些向量是通过在训练过程中,我们将3个矩阵相乘创建的。
注意,这些新的向量比词嵌入向量的维度要小。它们是64维的,同时词嵌入和encoder的输入输出都是512维的。它们不是必须要更小的,这是一个框架选择,为了使多头注意力机制的计算几乎恒定。
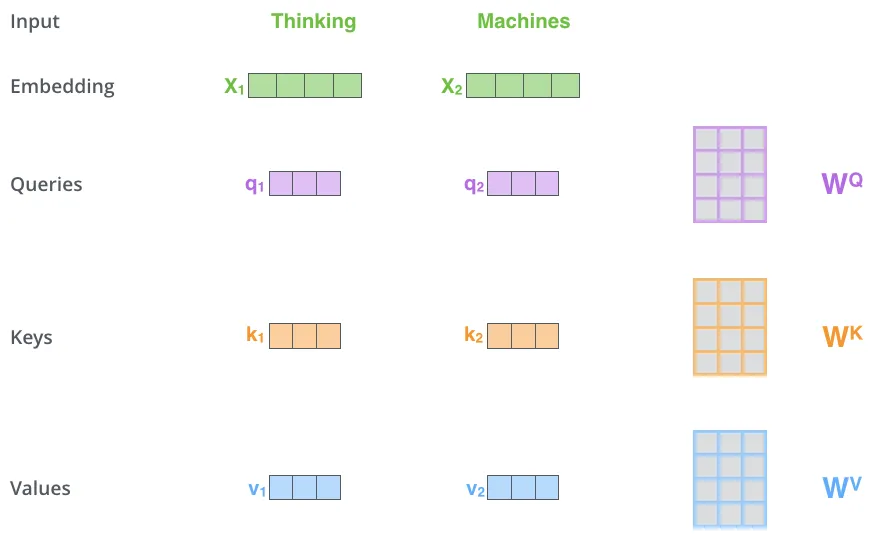
\(x1\) 乘以 \(W^Q\) 权重矩阵生成 \(q1\), \(q1\)就是query向量与那个词的联系。我们最终对输入语句的每一个词都创建了一个query,一个key和一个value来映射。
那么query,key,value向量是什么呢?
他们是一些抽象,这些抽象对于注意力的参考和计算有帮助。当你继续阅读完下面注意力机制是如何计算的,你就会非常清楚地明白你只需要知道这些向量所扮演的角色就可以了。
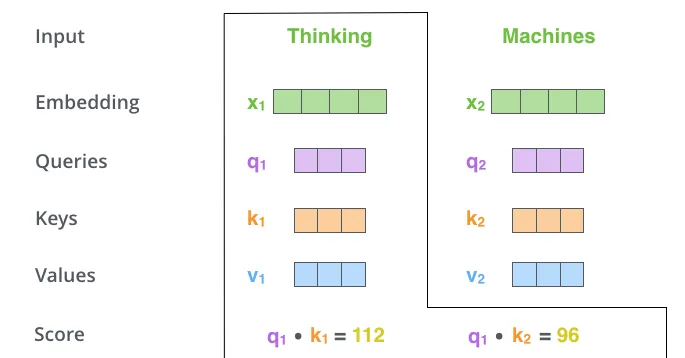
计算自注意力的第二步是计算分数。比如我们正在计算这个例子中的第一个词"Thinking"的自注意力。我们需要对输入中的每一个词对这个词进行打分。当我们encode某个位置的词时,这个分数决定在输入语句的其他词上我们投放多少注意力在这个位置上。
这个分数是通过query向量和key向量进行点乘来表示我们正在评分的这个词。所以当我们在计算位置#1上词的自注意力时,点乘q1和k1会是第一个分数。第二个分数是点乘q1和k2.
第三步和第四步是将这个分数除以8(论文中key向量维度的平方根——64。这样使得梯度更加稳定。这里也可以使用其他值,但这个是默认的),然后对结果进行一个softmax操作。softmax归一化分数,使得分数都是1以内的正数。
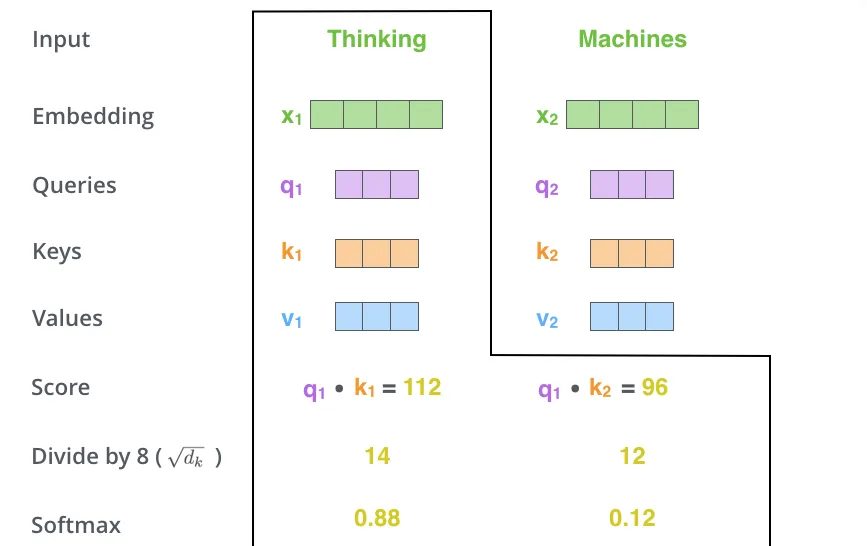
这个softmax分数决定每个词在这个位置上有多少表达。很明显,在这个位置的词本身分数会最高,但有时对于当前词的另外相关词才是有用的。
第五步 是每个value向量乘以softmax分数(在预备阶段是把他们加起来)。这里的直觉是保持我们想要关注的词的分数,打压不相关词的分数(例如通过给他们乘以一个很小的数比如0.001)
第六步 把这些权重向量累加起来。这步作为这个位置(第一个词)自注意力层的输出。
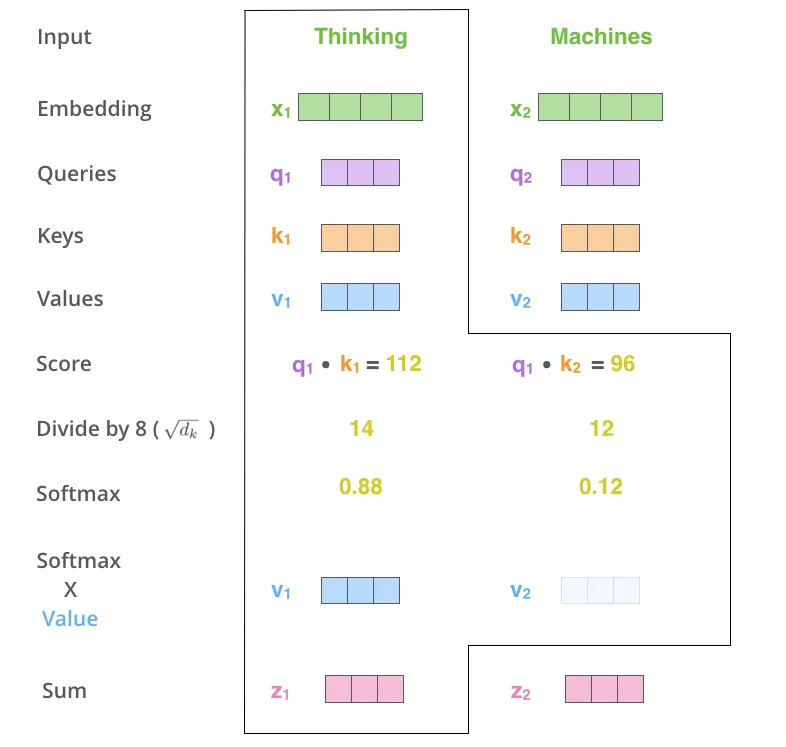
这就是自注意力计算的结果。这个结果向量我们可以送到全连接网络。在实际实现中,为了更快处理,计算过程是通过矩阵计算完成的。我们为了理解,在词粒度下来直观展现。
多头注意力
transformer的基本原理就上面介绍。这里还有一些其他细节使效果更好。例如:不同于在一维上互相进行注意力机制,transformer使用了多头注意力概念。
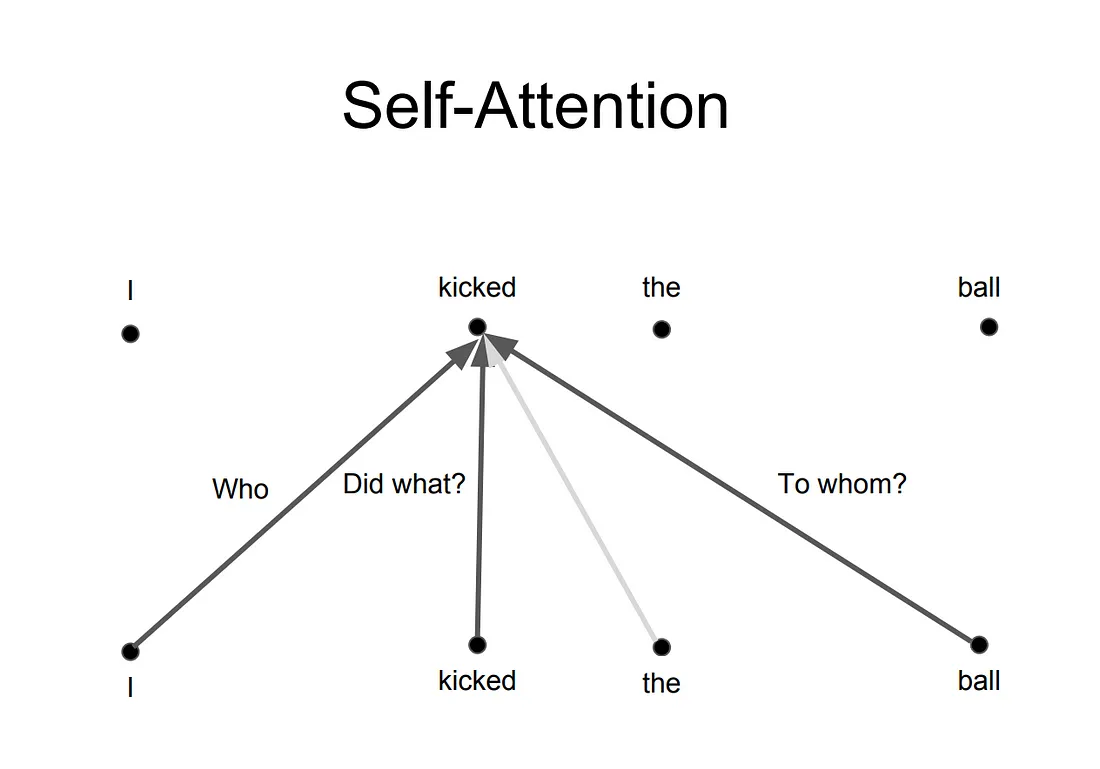
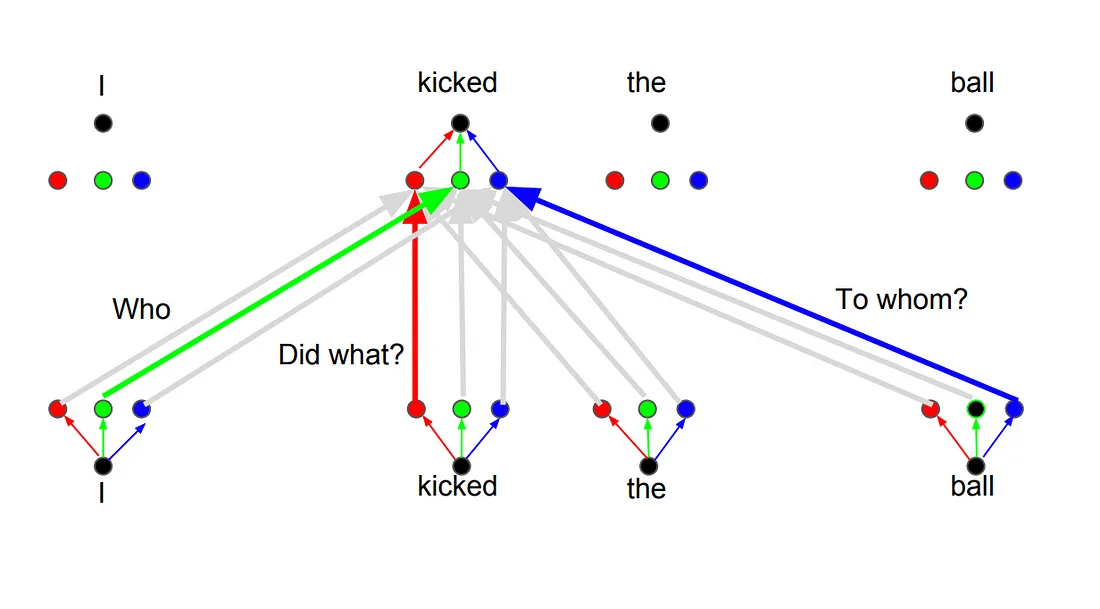
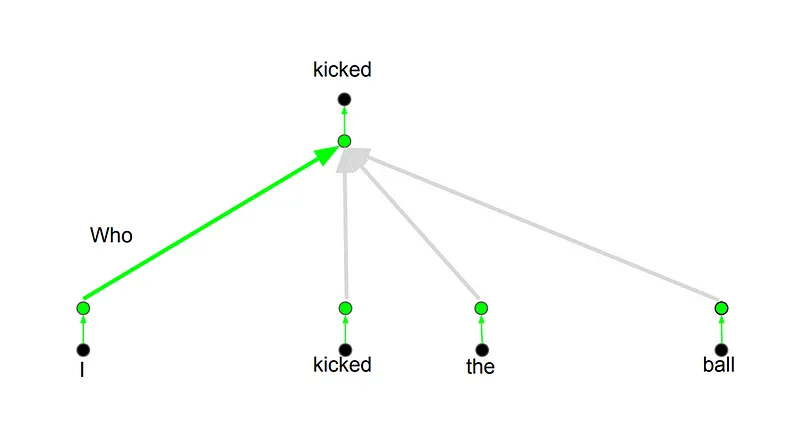
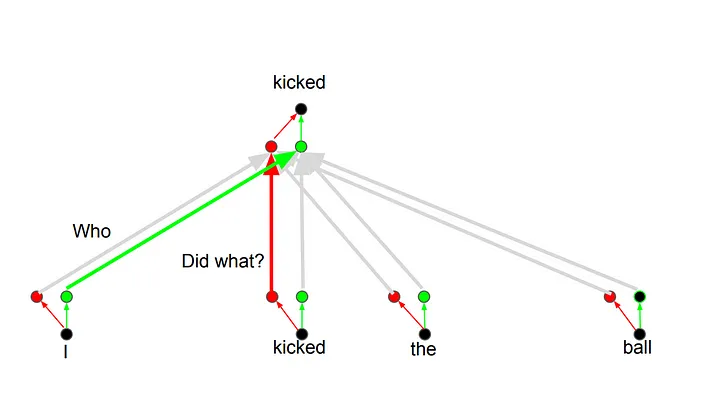
这背后的原理是无论何时你翻译一个单词时,根据你提问的类型,会对每个词有不同的注意力。下图做出了解释。例如,当你翻译句子"I kicked the ball"(我踢了球)中的"kicked"(踢)时, 你可以会问"Who kicked"(谁踢的) 。根据回答,这个词在其他语言的翻译会有变化。或者有其他问题,像"Did what?"(做了什么),等等……
位置编码(Positional Encoding)
另一个transformer重要的步骤就是在编码每个词时增加了位置编码。由于每个词在翻译时是位置相关的,所以编码时每个词的位置也是相关的。
总结
本文总结了Transformer的工作原理和这个机制为什么能用在序列转移上。如果你想更深入的了解模型原理和细节,我建议阅读下面的文字或视频。这些内容是我总结这篇技术的基础。
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Understanding LSTM Networks
- Visualizing A Neural Machine Translation Model
- The Illustrated Transformer
- The Transformer — Attention is all you need
- The Annotated Transformer
- Attention is all you need attentional neural network models
- Self-Attention For Generative Models
- OpenAI GPT-2: Understanding Language Generation through Visualization
- WaveNet: A Generative Model for Raw Audio
译者总结
- RNN 或 LSTM 有3类问题待解决:并行化问题,长短期依赖建模不明,位置距离是线性的。
- RNN注意力机制解决了长短期问题,但没有解决并行化和距离线性问题。
- CNN可以轻易地并行化,并且把距离计算变为了\(log(N)\),但不能解决信息依赖的问题。
- Transformer就是CNN+attention的结合体。解决了并行化、信息依赖问题,降低了距离计算的复杂度。
- 自注意力机制就是内部每个词的注意力计算。通过\(Q \cdot K\) 获得score,后面通过\(softmax\)进行归一化,再乘以\(V\)得到attention。